The Curious Case of Neural Text Degeneration
저자: Ari Holtzman, Jan Buys, Maxwell Forbes, Yejin Choi
(Allen Institute)
Purpose & Challenges:
- Analyzed the phenomena of text degeneration by neural machines
- Why does decoding with beam search from a strong language model lead to such degenerate text?
- Why does sampling from a truncated vocabulary distribution perform better than sampling from the whole distribution?
- What is the most principled method of truncation currently available?
Introduction:
- Open-ended NLG task는 input, context가 주어지면 그것을 바탕으로 자연어를 생성하는 task입니다. 이 논문에서는 open-ended task에서 생기는 문제점을 찾고 분석함.

- Context = X1..Xm
- Generate next n tokens to complete X1...Xm+n story.
- NLP task에서 좋은 결과가 나오는 대부분의 language model (GPT, Bert, Elmo 등)은 decoding 부분에서 beam/greedy search를 사용합니다. 즉, objective function이 maximization의 한 종류입니다. log likelihood, argmax, argmin, etc.
- Non-open-ended Generation tasks: machine translation, data-to-text generation, summarization.
- 좋은 결과가 나온 대부분의 language model은 beam search를 사용했는데, output content와 input content의 degree of freedom이 크지 않았기 때문.
- Open-ended NLG task에서 decoder부분에 beam search를 사용하면 자연스럽지가 않은 것을 확인할 수 있습니다.
GPT2 beam search:

GPT2 beam search
GPT2 sampling:

Top k sampling (k = 40)
Beam search는 high probability를 선택해서 자연어를 생성할 텐데 왜 자연스럽지 않을까?

- p = probability
- human text는 probability가 왔다 갔다 하는 반면에 machine text는 high probability zone에서 머물고 있는 것을 볼 수 있다.
- Beam에서 candidate을 선택하고, 그 다음 beam에서 candidate 단어를 선택하고, 또 그다음 beam에서 candidate 단어를 선택하게 되면, 그 값들이 계속 곱해져서 repetition문제가 생길거라 생각됩니다.
- 논문에서 제안하는 것은 nucleus sampling 방법인데 현재 GPT2에서도 사용되고 있다.
- Nucleus Sampling: majority of probability mass is concentrated in the nucleus of the distribution; a small subset of the vocabulary that spans across anywhere between one to a few hundred candidates.
- Top-k처럼 정해진 k번째까지의 candidate에서만 고려하는 것이 아닌, top-p 분포까지의 단어들을 고려하는 방안. candidate 개수는 p 분포 안에 있는 단어들이므로 많아지기도 적어지기도 합니다.
Why does Probability Maximization lead to degenerate text?
- Decoding objective function:

- RNN 구조에서 이것을 계산하기엔 어려움이 있음. (not tractable)
- 그래서 대안으로 approximation을 사용함: beam search 혹은 greedy decoding (beam size = 1)
- 앞에서 봤듯이, open-ended task에서 beam search를 사용한 text generation은 자연스럽지 못함.
- 질문: 디코딩할 때 beam search는 approximation을 하기 때문에 더 높은 probability를 가진 sentence를 찾지 못해서 문제가 있지 않을까?
- 논문에서의 답변: 더 근본적인 문제가 maximum-likelihood decoding objective에 있다.
Degenerative text: Repetition
- likelihood maximization approaches tend to loop into repeating the same sentence (Li et al, 2017, 2016)
- Beam search —> lack of diversity in the beam: candidates often only differ by punctuation or morphological variations. —> poor sequence generation quality


- Beam search를 통해서 선택되는 데이터 조합이 학습 데이터를 기반으로 생성이 되므로 처음 보는 조합일 경우 반복현상이 나타날 가능성이 존재하는 것일까?
GPT-beam search가 "i don't know" repetition을 시작할 때 나타나는 현상:

P("know" | "I don't") < P("know" | "I don't know. I don't") < P("know" | "I don't know. I don't know. I don't")
- transformer구조 특성상 next word prediction을 할 때 직전 context들의 weight를 가지고 있는데 이 부분 때문에 문제가 될 것이라 생각됨.

[http://jalammar.github.io/illustrated-transformer/](http://jalammar.github.io/illustrated-transformer/)- decoding 중에 계산된 값을 beam search로 아무리 찾아봤자 candidate diversity 낮으면 결국은 같은 단어가 나올 확률이 높아진다.
Why is naturally existing human text not the most probable text?
- Maxims of Communication(Grice, 1975):
- 사람은 대화할 때 당연하거나 뻔한 걸 말하기 꺼려하는 습성이 있어, highly probable text가 잘 등장하지 않는다. (하늘 참 파랗다...)
- 결론은 maximization대신 randomization을 사용해야 함.
Problems of using randomization:
- randomization을 하는 sampling 기법을 사용하면 repetition의 문제는 어느 정도 해결된다.
- In sampling based generation, at each time step we sample the next word Xi by drawing a word from the conditional language model:
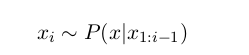
-
하지만, 일관성이 없는 incohorent text가 생성이 된다.
-
Sampling 분포에서 tail 부분에 있는 단어가 선택되면 계속 말이 안 되는 말만 생성하게 됨.
- 만약 tail부분의 한 단어가 선택 되었다면 그 다음 단어들도 생성될 때 바로 영향을 받기 때문.
-
Tail 부분이면 값들이 적을 텐데...
- paragraph level open-ended generation task에서는 크다!

- probability of sampling from the tail at time step i is e.
-
Full distribution에서는 tail의 probability mass가 약 0.31이고 20 step을 돌린다면 99.96%의 확률로 tail부분에서 단어를 선택하게 됨.
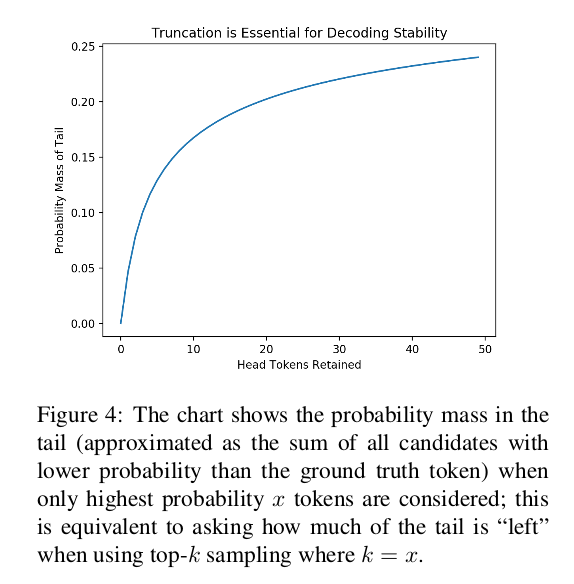
- Truncating distribution
- tail 부분을 제한하려 나온 게 top-k sampling 방법.
- 높은 probability순으로 k 번째까지만 candidate words로 고르는 방법.
Sampling with a Truncated Tail
Temperature Sampling: high temperature means low energy state
-
In probability, logits can be the energy.
-
logits = u1:|v|, temperature = t, V = vocabulary
Softmax 공식

t —> 0 means greedy decoding
t —> infinity means uniform sampling from the vocabulary
t E [0,1) shapes the distribution skewed towards high probability events (weakening the tail distribution)
- Lowering temperature increases the use of frequent words
Top-k sampling:
- GPT에서 사용하는 것처럼 top-k sampling이 자주 사용되고 있음.
- At each time step, top k next tokens are selected
- Then, the next word is sampled from those tokens.
- Beam search와 비슷하지만 probability distribution에서 top-k를 선택하게 됨.
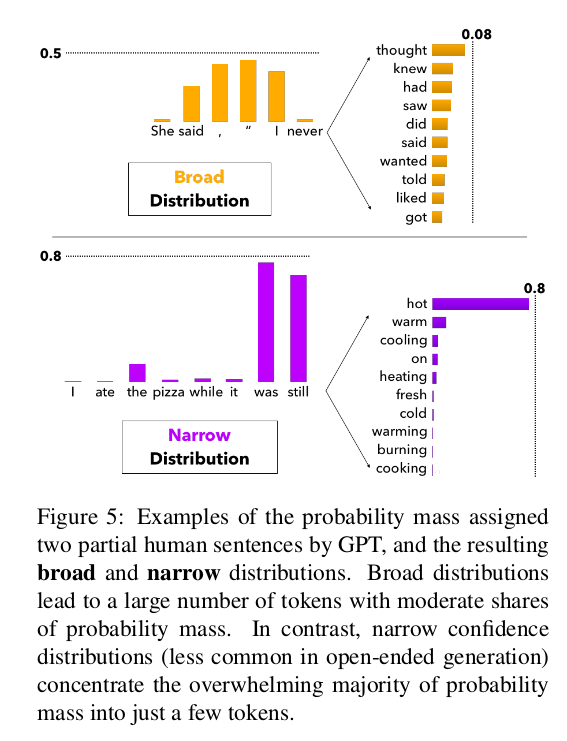
문제점:
- 위 그림처럼, 분포가 넓게 퍼져있으면 top-k 외에서도 좋은 candidate 단어가 있을 수도 있고, 아래 그림처럼 분포가 적으면, 단어수가 k보다 작을 수도 있어 효율성이 떨어진다고 주장함.
그래서 대안은 nucleus sampling 혹은 top-p sampling:
- Idea: select the highest probability tokens whose cumulative probability mass is greater than pre-chosen threshold "p" (그래서 top-p sampling)

- 여기서부터 논문의 contribution이라 볼 수 있는데 설득이 잘 안됨.

- cumulative density of the minimum k or p required to assign a non-zero probability to the gold prediction over a corpus of human-written text.
- top-k 보다 효율적으로 candidate word를 sampling 할 수 있음.

- Words diversity를 비교.
- top-k (k=16)과 top-p(p=0.9)와 비슷해 보임.
모델 결과:

- Top-k와 Nucleus sampling 둘 다 상당히 잘 나왔고, 자연스럽게 보이는데.. 아직도 설득력이 부족하다고 느껴집니다.
- K를 16으로 해야 정확한 비교가 되지 않았을까..
Experiments:
Language Model:
- Used GPT model (Radford et al, 2018)
Datasets:
- WritingPrompts (Fan et al, 2018)
- Input: context of 5 sentences with a maximum of 200 tokens
- Output: 200 next tokens

마치며..
- maximization algorithm (beam, greedy)로 디코딩을 하게 되면, 높은 확률로 등장하는 단어들을 뽑는다.
- 하지만, NLG를 할 때는 다양한 조합이 수 도 없이 많을 텐데, 학습 데이터가 아무리 많아도 그 수많은 조합의 일부에 불과하기 때문에 일정한 output token 이후엔 repetition으로 fitting이 되는 것 같다. 그다음부터는 어떤 단어가 와야 하는지 학습이 안되었기 때문이지 않을까 생각합니다.
- Randomization을 사용해도 일정한 길이의 텍스트 후에는 repetition현상이 나올 듯해 보입니다.
'자연어처리 (NLP)' 카테고리의 다른 글
| [NLG] [자연어 생성] [논문 리뷰] Multi-turn Dialogue Response Generation in an Adversarial Learning Framework (0) | 2019.10.31 |
|---|
